近日,IEEE国际计算机视觉与模式识别会议 CVPR 2021 (IEEE Conference on Computer Vision and Pattern Recognition) 大会审稿结果公布,考拉悠然科技共有4篇论文被收录,研究涵盖视觉分类、语义分割、时序语言定位、深度哈希等众多领域。
国际计算机视觉和模式识别大会(CVPR)素有计算机视觉领域的“奥斯卡”之称,凭借着严苛的论文录取标准,跻身全球AI顶会之流。实际上,CVPR是全球AI从业者检验自身AI“基本功”的“试金石”。
本文将汇总考拉悠然的4篇入选论文,并逐篇对内容抢先解读。
01
Jo-SRC: A Contrastive Approach for Combating Noisy Labels
关键字:噪声样本,视觉分类
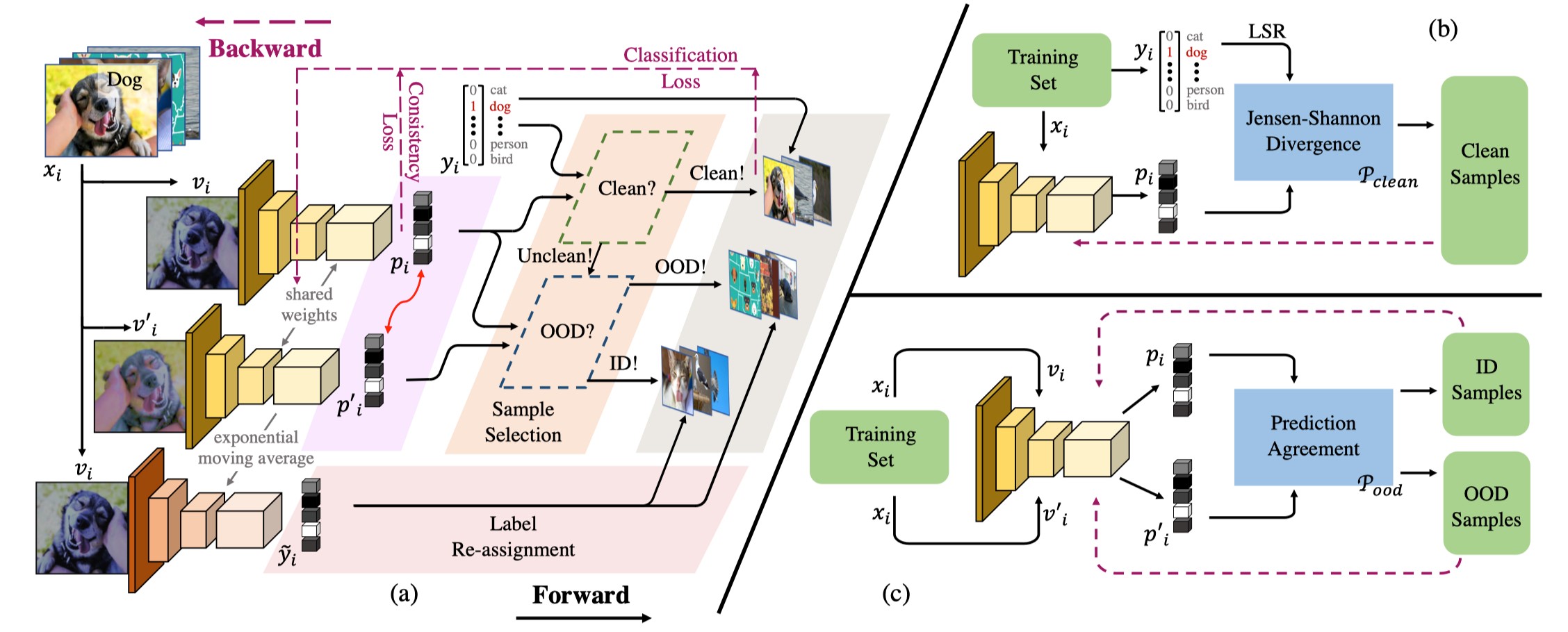
为了应对视觉分类任务中深度卷积神经网络对噪声样本过拟合的问题,作者提出了一个Jo-SRC方法。该方法采用两步式样本选择方法来进行干净样本、分布内噪声样本、分布外噪声样本的辨别:首先利用JS散度来评估样本是噪声样本的可能性,随后利用网络对同一样本两个不同视角的预测一致性来评估噪声样本属于分布外噪声的可能性。最后,作者提出对不同类别的样本进行不同方式的标签重分配,并引入了一个一致性正则化项来进一步辅助优化模型的识别能力。该算法在人造噪声数据集和真实场景噪声数据集上均取得了超越现有SOTA方法的性能。
02
Non-Salient Region Object Mining for Weakly Supervised Semantic Segmentation
关键字:非显著性区域,语义分割
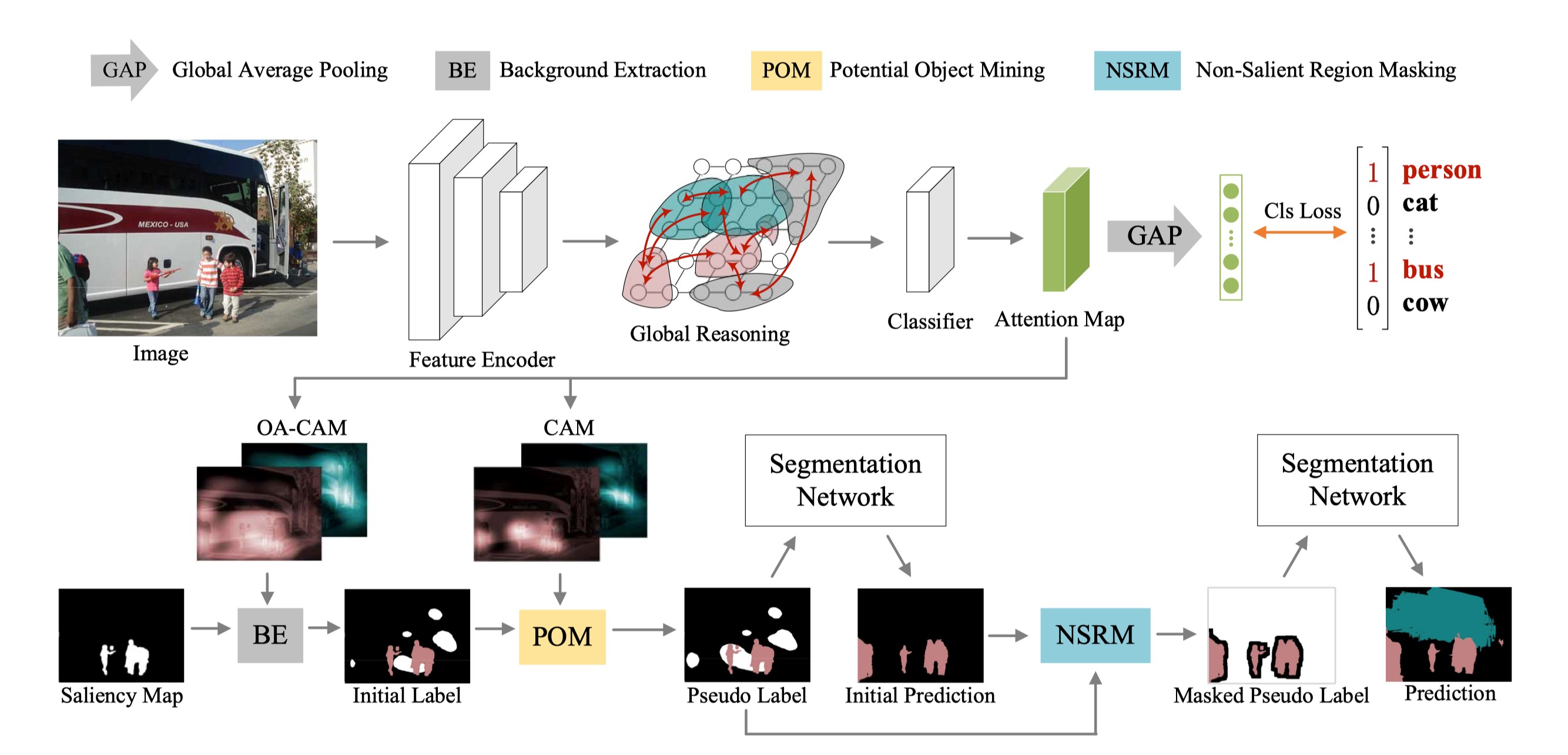
为了减轻视觉分割任务对密集标注信息的需求负担,作者着眼于弱监督语义分割场景。
与现有的主要关注图像显著性区域的方法不同,本文提出了一个非显著性区域目标挖掘算法。作者首先引入了一个基于图的全局推理单元,强化模型激活图像非显著性区域目标特征的能力。随后,作者提出了潜在目标挖掘模块和非显著性区域掩码模块来强化分割网络的自我校正能力。该算法在广泛使用的PASCAL VOC数据集上取得了超越现有的SOTA方法的性能。
03
Multi-stage Aggregated Transformer Network for Temporal Language Localization in Videos
关键字:Transformer,时序语言定位
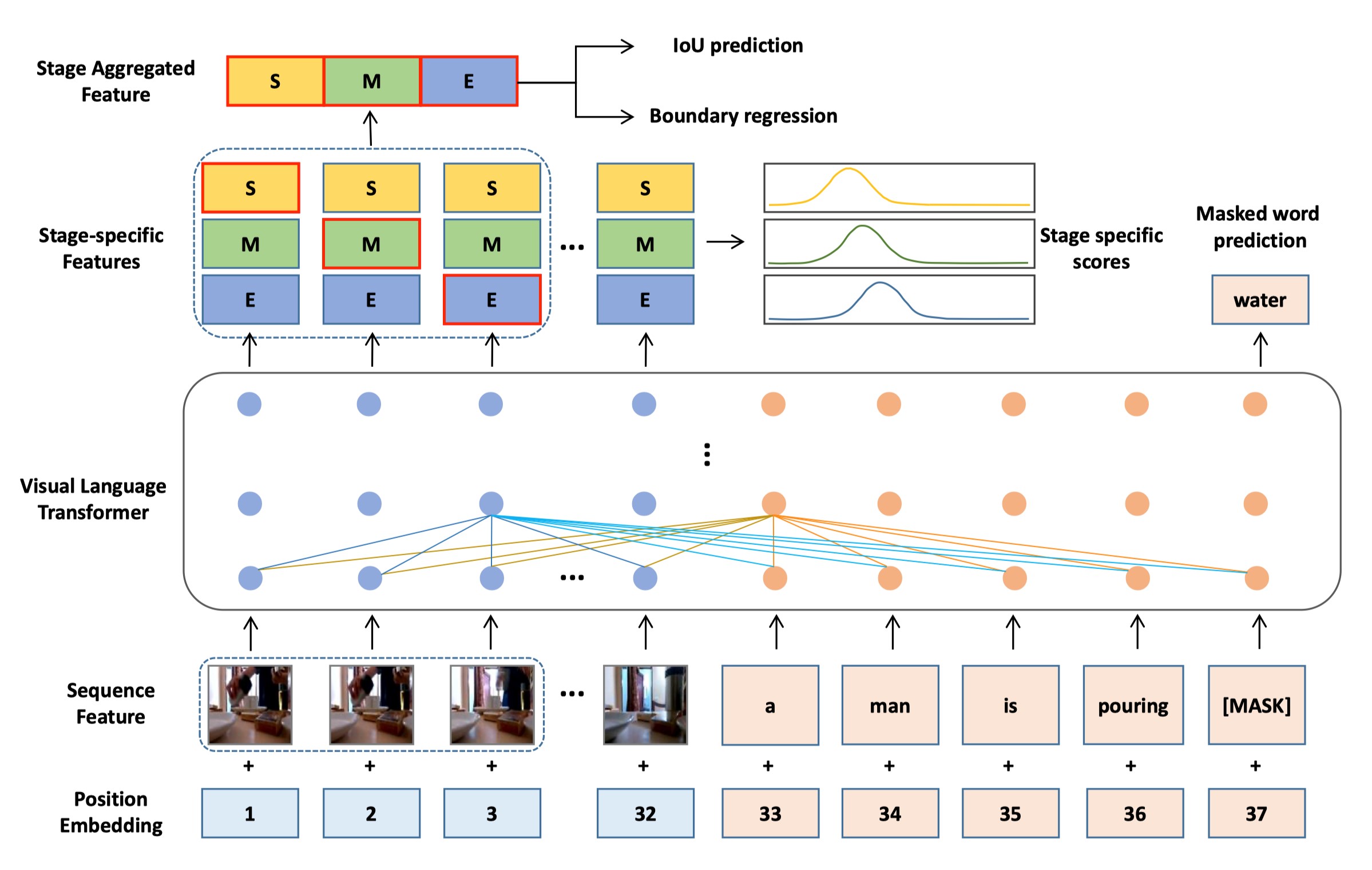
本文着眼于解决利用语言请求定位未修剪的视频中的特定时刻的问题。作者将这样一个时序语言定位问题简化为一个多阶段聚合Transformer网络。首先,作者引入了一个Transformer骨干网络来有效地对视觉内容和语言信息的细粒度对齐进行建模。随后,作者在此基础上提出了一个多阶段聚合模块,分别计算对应不同时刻阶段的特征表示。对于每一个时刻候选,作者将其不同阶段的不同特征表示聚合到一起以形成其最终的时刻特征表示。由于最终得到的时刻特征表示蕴含了特定于阶段的信息,因此易于被用来进行精准的时刻定位。最后,本文在时序语言定位数据集上的大量实验结果证明了本文算法的性能优于现有的SOTA方法。
04
Prototype-supervised Adversarial Network for Targeted Attack of Deep Hashing
关键字:对抗学习,深度哈希
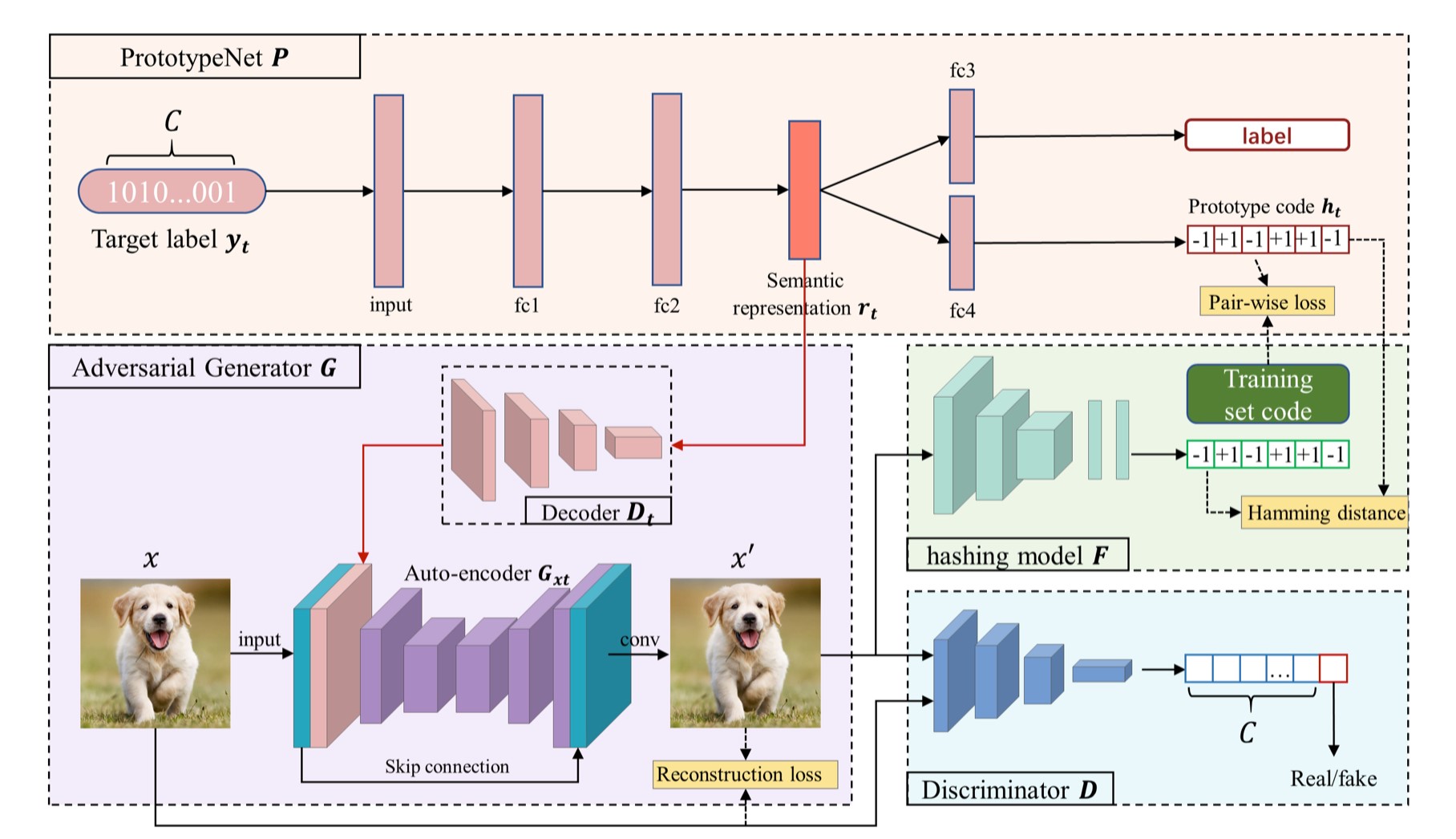
受益于深度卷积神经网络的强大表征能力,深度哈希在大规模图像检索领域取得了显著的成果。然而,深度哈希网络易受对抗样本攻击这个问题一直悬而未决。本文作者提出了一个基于原型监督的对抗网络(ProS-GAN)方法来应对有针对性的哈希攻击。本文是第一个提出利用生成式方法来攻击深度哈希网络的。本文的方法主要分为三部分:PrototypeNet、生成器和鉴别器。首先,PrototypeNet将目标抽象为语义表示来学习目标的原型码。随后,作者将目标的语义表示和原始图像输入生成器来进行有针对性的攻击,在这个过程中,原型码被用来监督对抗样本的生成。最后,作者通过生成器和鉴别器之间的互相对抗来促使生成的样本在视觉上具有真实性,在语义上具有丰富的信息。大量的实验结果证实与SOTA方法相比,本文方法可以有效地生成具有更优的攻击性能和传递性的对抗样本示例。
截至2021年2月,考拉悠然已公开发表AI顶级学术期刊会议论文300+篇,获得最佳论文奖15+项。不仅如此,考拉悠然在加大学术研究投入的同时还积极推动行业技术发展与产业落地。依托OSMAGIC码极客人工智能操作系统,聚焦城市数字化治理与产业数字化转型两大AI商业应用场景,考拉悠然深入产业落地的“试炼场”,检验AI“基本功”。未来,考拉悠然还将继续推动AI产业落地,完善行业生态建设,为千行百业持续赋能,与合作伙伴构建万物AI的美好世界。






